
Im Zusammenhang mit der Suchmaschinenoptimierung ist immer wieder von den so genannten META-Tags die Rede. Vielfach geben sich Seitenbetreiber große Mühe derartige Tags optimal anzupassen und somit ihre Seite besser in Google und anderen Suchmaschinen auffindbar zu machen. Doch was ist das eigentlich genau und warum können META-Tags in einigen Fällen sehr wichtig sein?
Grundsätzlich stellen META-Tags Hintergrundinformationen zu Websites dar. Einzelne HTML-Seiten werden auf diese Art und Weise mit Angaben versehen, die in der Regel nicht für den User selbst, sondern für Robots, Browser und andere Dienste gedacht sind. Dies muss jedoch nicht bedeuten, dass META-Tags für den User eine Seite keinerlei Relevanz besitzen.
Sichtbar werden Title (welcher im eigentlichen Sinne gar keine META-Information ist aber sehr oft im Zusammenhang damit genannt wird) sowie die Description vor allem im Zuge von Suchanfragen bei Google und Co. Clevere Webmaster gestalten ihr "Snippet" bei Google so, dass es zum Klicken einlädt und darüber hinaus genau wieder gibt, welche Inhalte einen der entsprechenden erwarten.
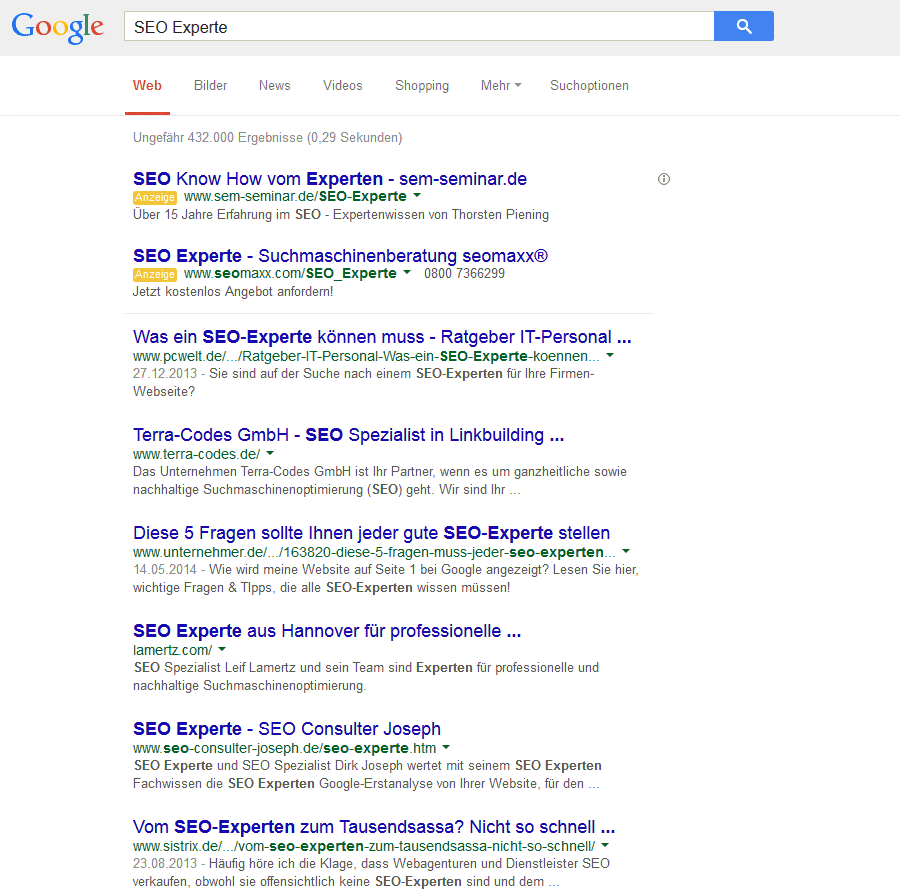
In diesem Bild ist eine typische Suchergebnis-Liste der Suchmaschine Google zu sehen. Der obere markierte Bereich stellt die Überschrift einer Seite dar. Zugleich wird hier seitens der Suchmaschine meistens genau das eingeblendet, was im TITLE-Tag (quasi als Überschrift) auf der entsprechenden Seite steht. Der kurze Erklärungstext darunter ist in der Regel dass, was unter meta name="description" im head-Bereich einer Seite zu finden ist.

Generell gehörten META-Tags, sowie auch der TITLE immer in den Head-Bereich einer Seite, da es keine Inhalte im herkömmlichen Sinne sind. Bei des Auswahl von TITLE und Description sollte auf Folgendes geachtet werden:
Beachtet man diese Grundregeln konsequent und erstellt man für jede einzelner seiner (relevanten) Unterseiten entsprechende Tags, so ist man hinsichtlich der Onpage-Optimierung der eigenen Seite bereits auf einem guten Weg.
Das detailliere Befassen mit den zuvor genannten Tags, ist wohl für jeden Webmaster eine sinnvolle Sache, dem ein möglichst optimales Google-Ranking am Herzen liegt. Strittig ist hingegen, ob es heutzutage wirklich noch etwas bringt, konsequent auf die Keyword-Tags der META-Informationen zu setzen.
Hierzu ein Video von Google Webmaster:

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Google äußert hier also klipp und klar, META-Keywords nicht zu für die organische Suche zu verwenden - auch nicht nur "ein Bisschen". Allerdings ist Dies lediglich ein offizielles Statement seitens Google. Andere Suchmaschinen nutzen den Keyword-Tag sehr-wohl und ziehen diesen zur inhaltlichen Bewertung einer Website mit heran. Darüber hinaus werden die META-Keywords von vielen Seitenbetreibern gerne zur Dokumentation dahingehend verwendet, auf welche konkreten Keywords man eine bestimmte Unterseite optimiert / ausrichtet.
Grundsätzliches Fazit zu Keyword-Tags bleibt: Es schadet zumindest nicht, diese auszufüllen und sich konzeptionelle Gedanken zur Auswahl der am besten passenden Keywords zu machen.
Die META-Tags ermöglichen es unter anderem auch, direkte Anweisungen an den Crawler zu geben. Dies geschieht, über meta name="robots", siehe unten:

Lässt man diesen META-Tag weg, so verwenden Bots die Default-Werte "index, follow", was bedeutet, dass der Bot die entsprechende (Unter)Seite indexieren und den dort auffindbaren Link folgen soll. Im Codebeispiel oben, wird dem Bot quasi "Leseverbot" erteilt. Dieser soll in dem Fall die Seite nicht indexieren und den Links nicht folgen.
Die gesamte Liste an möglichen Optionen lautet wie folgt:
Übrigens: Der Tag name="robots" kann auch durch name="googlebot" ersetzt werden. In dem Fall wird explizit nur der GoogleBot angesprochen. Auf diese Art und Weise ist es zum Beispiel möglich, GoogleBot und andere Bots unterschiedlich zu behandeln, in dem man etwa beide Tags integriert und für jeden Zugriff unterschiedliche Handlungsanweisungen definiert.
Neben Description, Keywords und den Tags für den Robot, gibt es noch einige weitere META-Angaben, die vielfach oder zumindest im Bezug auf Google als überflüssig angesehen werden. Dazu zählen unter anderem:
In Spezialfällen oder auch dann, wenn man nicht (nur) Google adressiert, können diese Tags jedoch nach wie vor verwendet werden. Ein solcher "Spezialfall" kann zum Beispiel eine Seite sein, die vollständig in Flash gestaltet wurde - und zwar so, dass diese einen Crwaler keine Chance gibt, die enthaltenden Informationen zu erfassen. Hier kann es dann mitunter sinnig sein, Crawlern mit auf den Weg zu geben, in welcher Sprache eine Seite vorliegt oder wann dieser das letzte Mal geändert wurde.